PVDI SOP (Standard Operating Procedure)
이 문서는 PVDI 표준운영절차 (Standard Operating Procedure)를 기술합니다.
서버 관련
PVDI Node 종료/재구동 절차
점검 등의 목적으로 pvdi node를 안전하게 종료/재구동하는 방법
Halt, shutdown, reboot등의 명령으로 한번에 종료/재구동 하는것은 안전하지 않습니다. 아래와 같이 순차적으로 진행해야 서버가 안전하게 종료/재구동 할 수 있습니다.
관리자 페이지에서 해당 node에서 구동중인 vm을 모두 종료합니다.
mastervm을 node에서 종료 합니다.
# xl shutdown [mastervm ID]구동중인 vm이 있는지 다시 한번 체크합니다.
# xl listFc san, iscsi등을 이용하여 ocfs2를 사용한다면 해당 볼륨(/data)을 unmount 합니다. 로컬 디스크를 사용한다면 해당 작업은 생략합니다.
# umount /data시스템을 종료/재구동 합니다.
# reboot # halt
mastervm 구동
# cd /data # xl create [mastervm].cfg
아래 Node, Master VM 점검 사항을 진행 후 관리자 페이지에서 vm을 구동합니다.
PVDI Node 서비스 점검 사항
pvdi node가 부팅된 후 서비스 점검 사항
pvdi node에 nginx(web server)와 was(web application server), pemon(monitoring daemon) 총 3개의 데몬이 구동중이어야 정상적으로 작동합니다.
FC San, Iscsi등을 이용하여 stoage(ocfs2)를 사용한다면, 해당 storage가 정상적으로 mount되어 있는지 확인합니다.
# mount | grep /dataStorage(/data)가 mount되어 있지 않다면 아래 명령으로 mount할수 있습니다.
# mount /data해당 노드에 ssh 접속후 web server(nginx) daemon 상태 확인
# ps -ef | grep nginxpvdi web application daemon 상태 확인
# ps -ef | grep uwsgiPemon daemon 상태 확인
# ps -ef | grep pemonNginx, was, pemon 구동 만약 위 3개의 process가 구동중이지 않다면 아래와 같이 구동할수 있습니다.
# /etc/init.d/nginx start # su – orchard $ cd ~/pvdi/scripts $ ./pvdi_was start $ ./pemon start
관리자페이지에 접속후 해당 노드 상태를 확인하여 노드 상태가 dead라면 recovery를 시도하여 복구합니다.
pvdi 버젼 정보 확인
# cat /home/orchard/pvdi/docs/VERSION
Master VM 서비스 점검 사항 (단일 Master VM)
Master vm이 하나로 구성되어 있는 경우, pvdi의 mastervm이 구동된 후 서비스 점검 사항
pvdi master vm은 node에 nginx(web server)와 was(web application server) 총 2개의 데몬이 구동중이어야 정상적으로 작동합니다.
해당 노드에 ssh 접속후 web server(nginx) daemon 상태 확인
# ps -ef | grep nginx
- 2-1. pvdi web application daemon 상태 확인
# ps -ef | grep uwsgi- 2-2. pvdi2 web application daemon 상태 확인
# ps -ef | grep pvdi_uwsgi.ini # ps -ef | grep pvdi_uwsgi_web.ini # ps -ef | grep graphite_uwsgi.ini # ps -ef | grep carbon
- 3-1. pvdi nginx, was 구동 만약 위 2개의 process가 구동중이지 않다면
아래와 같이 구동할수 있습니다.
# /etc/init.d/nginx start # su – orchard $ cd ~/pvdi/scripts $ ./pvdi_was start
- 3-2. pvdi2 nginx, was 구동 pvdi2 버젼에서는 process가 추가되어 아래와
같이 추가로 구동되어야 합니다.
# /etc/init.d/nginx start # su – orchard $ cd ~/pvdi/scripts $ ./pvdi_was start $ ./pvdi_was_web start $ ./graphite_was start $ /opt/graphite/bin/carbon-cache.py start
db backup data 확인 db backup data(mysql dump file) 저장 경로는 아래와 같습니다.
# ls -al /home/orchard/db_backupdb backup log 확인
# cat /home/orchard/pvdi/var/log/db_backup/db_backup_{date}.logpvdi 버젼 정보 확인
# cat /home/orchard/pvdi/docs/VERSION``
Master VM 서비스 점검 사항 (HA 구성)
Master VM이 HA구성 되어 있는 경우, mastervm이 구동된 후 서비스 점검 사항
2개의 Master VM(master, slave)중 둘중 하나에 ssh 접속 후 확인할 수 있습니다.
Master node의 Cluster resource 확인
# crm resource status Resource Group: DBServer ClusterIP0 (ocf::heartbeat:IPaddr2) Started ClusterIP1 (ocf::heartbeat:IPaddr2) Started DBFS (ocf::heartbeat:Filesystem) Started Links (ocf::heartbeat:symlink) Started Dbase (ocf::heartbeat:mysql) Started Master/Slave Set: ms_r0 [r0 ] Masters: [ mastervm01 ] Stopped [ mastervm02 ]
각 resourse의 “Started”상태 확인, Masters의 현재 활성화된 master-vm의 Hostname을 확인하면 됩니다.
Cluster resource 구동 만약 Started되지 않고, Stopped되어 있다면 아래 명령으로 구동할 수 있습니다.
# crm resource startNginx 구동 확인
# ps -ef | grep nginxwas 구동 확인
# ps -ef | grep uwsginginx, was 구동
# /etc/init.d/nginx start # su – orchard $ cd ~/pvdi/scripts $ ./pvdi_was start
PVDI Node Hang
운영중인 pvdi node서버가 갑자기 hang 되거나 reboot 되었을 때
갑작스럽게 hang이 걸렸을때 경우에 따라 관련 log가 서버에 기록되지 않을수 있습니다. 가능하다면 console 화면에 나타나는 error message를 사진등을 찍어두는 편이 좋습니다.
System log 확인
# less /var/log/messagesdom0 메모리 (pagecache) 관련 문제 /var/log/messages에 Call Trace: alloc_xenballoned_page, vfs_ioctl등이 찍혀있다면 crontab에 아래 command를 추가하여 주기적으로 dom0의 pagecache 삭제하도록 변경합니다.
# crontab -e 0 * * * * sync && echo 1 > /proc/sys/vm_drop_caches
ocfs2 관련 문제 /var/log/message에 o2net:No longer connected to node등의 메시지가 보인다면 ocfs cluter간의 내부 통신망 문제입니다. 내부 통신망에 연결은 문제가 없는지 확인하고, ocfs2 heartbeat의 threshold값을 높게 설정합니다.
# vi /etc/defaults/o2cb O2CB_HEARTBEAT_THRESHOLD=91 # /etc/init.d/o2cb reload
그밖의 알수 없는 원인으로 hang,reboot되었을때 인프라솔루션개발팀에 문의합니다.
PVDI Node 노드간의 시간 동기화 문제
서버간의 서버시간이 차이가 많이 나 ocfs cluster간 timestamp 문제로 장애가 발생할때 Node, mater vm간의 서버 시간이 맞지 않아 장애 추적등의 관리가 어려울때
NTP서버를 두어 각 노드간의 서버 시각을 동기화 할 수 있습니다.
Ntp 서버 설정
# vi /etc/ntp.conf server [ntpserver ipaddress]
Ntp 적용, 데몬 재시작
# /etc/init.d/ntp stop # ntpdate -s [ntpnserver ipaddress] # /etc/init.d/ntp start
다른 노드와 시각 동기화 확인
# date
VM 구동 실패시
VM 구동이 실패하였을때
해당 Node의 상태 확인 관리자 페이지의 nodes 메뉴에서 Node의 Status가 Alive인지 확인합니다.
Node의 유휴자원 확인 관리자페이지의 nodes 메뉴에서 node의 Free memory가 VM을 구동할 여유가 있는지 확인 합니다.
storage mount 확인
# mount | grep /data
스토리지 점검 사항
Storage(/data)가 정상적으로 작동하지 않을때 점검 사항
ocfs2의 상태 확인
# /etc/init.d/o2cb status Driver for "configfs": Loaded Filesystem "configfs": Mounted Stack glue driver: Loaded Stack plugin "o2cb": Loaded Driver for "ocfs2_dlmfs": Loaded Filesystem "ocfs2_dlmfs": Mounted -- mounted 확인 Checking O2CB cluster uvdi: Online -- online 확인 Heartbeat dead threshold = 91 Network idle timeout: 6000000 Network keepalive delay: 2000 Network reconnect delay: 2000 Checking O2CB heartbeat: Active --- active 확인
ocfs2 재시작 및 mount
# /etc/init.d/o2cb restart # mount /data
네트워크 점검 사항
네트워크 관련 점검 사항
네트워크의 경우 간단히 ping 테스트로 확인합니다. 각 interface별로 gateway, node등으로 ping test를 진행합니다.
Bonding 확인 bonding이 되어 있는 경우 아래의 명령으로 각 interface의 상태를 확인 할 수 있습니다.
root@localhost ~: cat /proc/net/bonding/bond0 Bonding Mode: fault-tolerance (active-backup) Currently Active Slave: eth0 -- 현재 active된 interface MII Status: up -- bond0 status , up되어 있는지 확인 Slave Interface: eth2 MII Status: up -- slave interface status Speed: 1000 Mbps Duplex: full Slave Interface: eth1 MII Status: up -- slave interface status Speed: 1000 Mbps Duplex: full
이중화 구성으로 하나의 interface가 down되어도 서비스 가능하지만, 네트워크 담당자에게 알려주는 것이 좋습니다.
Bridge 확인 각 interface는 bridge(가상 스위치)를 이용하여 vm에 network를 할당합니다.
# brctl show bridge name bridge id STP enabled interfaces xenbr0 8000.001e67166064 no eth0 xenbr1 8000.001e67166065 no eth1
Ocfs2 재시작 및 mount
# /etc/init.d/o2cb restart # mount /data
네트워크 정보 변경후 VM의 네트워크 작동 불가
Node의 bridge network 정보를 변경한뒤 vm의 네트워크가 작동하지 않아 접속이 불가능할 때
Bridge interface의 gateway의 변경, ip 변경등을 네트워크의 경우 bridge network이 재시작되어 vm의 네트워크가 단절되게 됩니다.
node의 bridge network을 아래와 같이 변경한 경우
# /etc/init.d/networking restart혹은
# ifdown xenbr[x] # ifup xenbr[x]
위와 같이 network을 변경하고 interface를 재시작할 경우 vm의 네트워크는 모두 단절됩니다. 이땐 해당 노드의 VM을 재부팅하면 정상적으로 네트워크가 작동됩니다.
Network 재시작 없이 변경 아래와 같이 변경하면 bridge network의 재시작 없이 (VM의 재구동없이) 변경 할 수 있습니다.
# ifconfig xenbr0 [ip_address] subnet [subnet_mask] # route add default gw [gateway]
GoldenVM을 다른 Zone으로 복사하여 사용 할 경우
gvm(goldenvm)을 다른 node 또는 다른 zone에 복사하여 사용 할 경우
공유형 스토리지를 사용할 경우 gvm을 같은 zone에서 공유하기에 문제가 없지만 로컬디스크를 사용할 경우 해당 기능은 제공되어지지 않습니다. 해당 기능은 추후 업데이트 버젼에서 추가 검토중이며 현재는 수동으로 gvm을 카피하는 작업이 필요합니다. 단순히 gvm을 cli로 카피하는 작업이지만 작업 중 문제가 발생할 수 있는 상황이 있으므로 아래 주의사항을 반드시 참고하여 진행합니다.
복사가 될 zone에 관리자 페이지에서 신규 gvm을 생성 합니다. “관리자 페이지 -> admin login -> 상위 메뉴 중 Golden VM -> Add”
- Name : 사용자 정의
- Method : New 선택
- Type : 원본 gvm과 동일하게 선택
- OS : 원본 gvm과 동일하게 선택
- Disk Size : 원본 gvm과 동일하게 입력
- Authentication Mode : Internel 선택
- ID : 원본 gvm에 ID
- Password : 원본 gvm에 PWD
생성이 완료된 후 해당 gvm을 “start”하여 구동을 시킨 후 “stop”하여 종료를 합니다. 이 과정은 신규 gvm을 생성 후 cofnig 파일을 생성하는 작업으로 status가 “running” 상태로 확인이 된 후 종료를 합니다.
원본 gvm의 현재 상태와 disk uuid 정보를 확인 합니다.
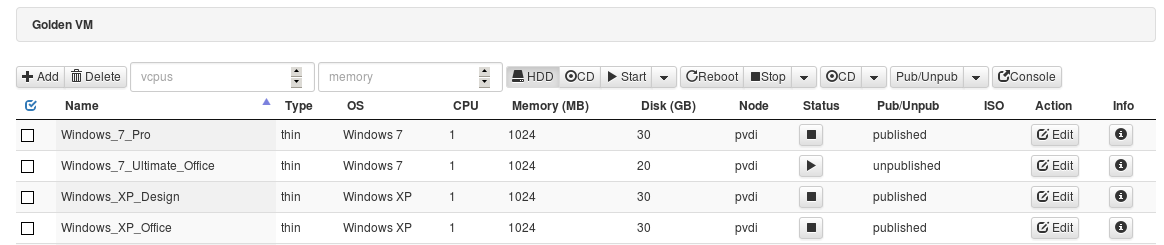
- “Windows_7_pro” gvm 을 복사할 경우 첫번째로 “Node” 정보를 확인, 두번째로 오른쪽 끝에 info 메뉴를 클릭하여 “Disk UUID” 를 확인합니다.
- 주의사항은 “Windows_7_Ultimate_Office”와 같이 status가 “running” 상태에 gvm을 복사시 해당 gvm이 손상 될 수 있습니다.
- 반드시 status를 먼저 체크하여 “halted”인 상태에서 작업이 진행되어야 합니다.
위에서 첫번째로 확인 된 “Node”로 ssh 접속을 합니다.
# ssh root@"Node ip" -p"ssh port" ex) ssh root@192.168.0.20 -p22
해당 Node의 상세 정보는 “관리자페이지 -> admin login -> 상위 메뉴 중 Nodes” 에서 확인이 가능 합니다.
접속이 이루어 졌다면 두번째로 확인 된 “Disk UUID” 정보로 gvm을 확인합니다.
# cd /data/gvm # ls -al ./"Disk UUID" ex) ls -al ./1943409b-b9fb-4e18-acdd-f5eb5390e5ef -rw-r--r-- 1 root root 14428966912 1월 22 12:24 ./1943409b-b9fb-4e18-acdd-f5eb5390e5ef`
해당 gvm을 위와 같이 검색이 되어 존재한다면 아래의 scp 명령어로 복사를 할 목적지 zone의 node로 카피하여 줍니다.
# scp -P"ssh port" /data/gvm/"Disk UUID" "목적지 Node ip":/data/gvm/ ex) scp -P22 /data/gvm/1943409b-b9fb-4e18-acdd-f5eb5390e5ef 192.168.0.21:/data/gvm/
카피가 완료되었다면 목적지 node로 ssh 접속을 합니다.
# ssh root@"목적지 Node ip" -p"ssh port" ex) ssh root@192.168.0.21 -p22
접속이 이루어 졌다면 복사가 완료된 gvm을 확인합니다. 확인 방법은 5번과 동일합니다.
# cd /data/gvm # ls -al ./"Disk UUID" ex) ls -al ./1943409b-b9fb-4e18-acdd-f5eb5390e5ef -rw-r--r-- 1 root root 14428966912 1월 22 12:24 ./1943409b-b9fb-4e18-acdd-f5eb5390e5ef
복사가 완료된 gvm이 확인되었다면 1번에서 신규로 생성한 gvm에 “Disk UUID” 정보를 확인한 뒤 복사를 한 gvm으로 변경합니다. 해당 작업시 신규 gvm에 “Disk UUID”를 반드시 중복 체크 후 진행합니다.
# cd /data/gvm # mv ./"신규 gvm Disk UUID" ./"신규 gvm Disk.UUID".bak ex) mv ./8644c84e-76fc-4c2d-9eb9-847ad6d78c01 ./8644c84e-76fc-4c2d-9eb9-847ad6d78c01.bak # mv ./"복사 gvm Disk UUID" ./"신규 gvm Disk UUID" ex) mv./1943409b-b9fb-4e18-acdd-f5eb5390e5ef ./8644c84e-76fc-4c2d-9eb9-847ad6d78c01
변경 작업이 완료된 후 관리자 페이지로 접속하여 신규 gvm을 다시 start하여 console 접속으로 확인합니다.
정상적인 부팅이 확인이 되었다면 기존 사용방법과 동일하게 catalog를 생성하여 배포가 가능합니다.
클라이언트 관련
VM 상태가 Booting일 경우
client로 로그인후 VM의 계속 Booting일 경우
- 관리자 페이지에서 해당 VM의 Console 접근 해당 VM에 console 접근후 VM을 정상적으로 올라와 있는지 확인 합니다.
- RDP (3389) 활성화 확인 해당 VM이 정상적으로 RDP가 열려있는지 확인합니다. “제어판 – 시스템 – 원격설정 – 원격데스크톱 – 모든 버전의 원격 데스크톱을 실행 중인 컴퓨터에서 연결허용” 선택
- RDP(3389) 방화벽 확인 해당 VM의 3389포트로의 방화벽이 작동하고 있는지 확인후, 해당 포트로 접속을 허용하게 설정합니다.
VM Connect 클릭시 접속 불가능
client로 로그인후 VM Connect 버튼을 눌러을때 아래와 같은 메시지가 보이면서 접속되지 않을때
- 방화벽 확인 client가 설치된 PC에서 pvdi node로 ssh port 22 접속이 가능해야 접속할 수 있습니다. 해당 노드로 22번 접속이 가능한지 확인합니다.
- pvdi client가 설치 경로 확인 pvdi client가 설치된 경로에 한글이나 공백등의 문자가 포함되어 있는지 확인합니다. 예를 들어 “C:\사용자\홍길동\다운로드”에 pvdi client가 설치되어 있는 경우 client가 정상 작동하지 않습니다.
- Server.xml 파일 삭제 경로에 문제가 없는데 문제가 발생한다면 “pvdi설치디렉토리\var`.pd_client:raw-latex:server.xml”을 삭제하여 서버 및 사용자 정보를 reset 합니다.